3. Patient Data
The database is setup to host data in so-called Projects (Project) and Archives (Archive). A project can be set up with specific configurations that holds for all data that resides in that project. A project is the umbrella for one or multiple archives. The archives hold the image data and derived data thereoff. A user can have specific permissions to performs actions on a project/archive or the data residing in the project/archive.
In the archive, the actual patient imaging data is stored following the DICOM standard of Patient, Study, Series, Instance. A Patient can have one or more Study objects (e.g. when the patient has had multiple examination dates or visits to a clinic). Each Study consists of one or multiple Series (e.g. an X-Ray, CT-Scan, Fundus image, etc). Each Series typically consists of one Instance, which contains the actual image data. In some cases a Series can contain multiple Instance objects (e.g. Slice based DICOM scans) which together make a single Series.
All derived results, such as Algorithm results, are stored in the database and are linked to the Patient, Study, Series or Instance object to which the derived result belongs.
3.1. Algorithm
To add a new algorithm, click the Add button (or Add algorithm), and to change an existing algorithm, click on the name of the algorithm you want to change. This will open a new page to edit the algorithm (Fig. 3.4).
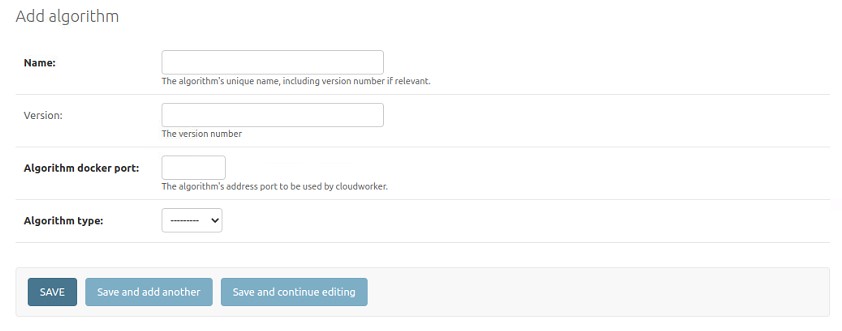
Fig. 3.4 Edit algorithm
The following fields are shown:
- Name*:
The name of the algorithm.
- Version:
The version of the algorithm. For example, 1.2.1
- Slug*:
The slug of the algorithm. This value will be internally used in the database and should never be changed after the algorithm is created.
- Algorithm type*:
Can currently only be: “cad4tb”. The algorithm type is used for internal configurations on how to save the results of the algorithm in the database.
* Required fields
3.2. Project
To add a new project, click the Add button (or Add project), and to change an existing project, click on the name of the project you want to change. This will open a new page to edit the project (Fig. 3.6).
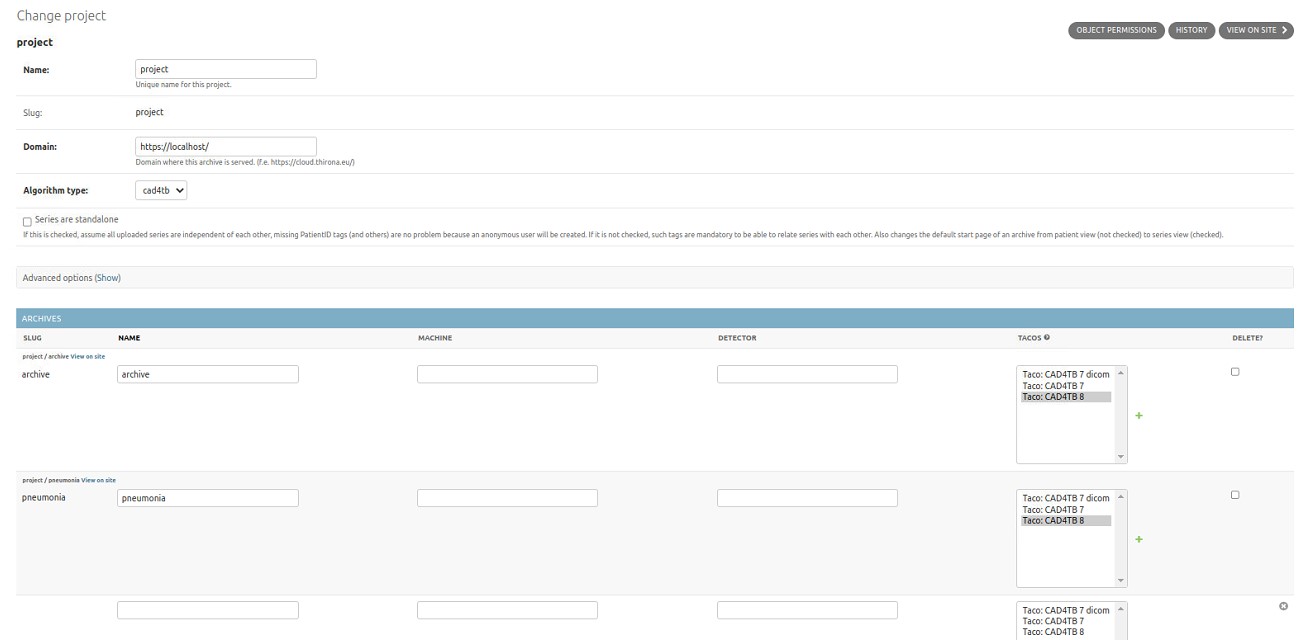
Fig. 3.5 Edit project
The following fields are shown:
- Name*:
The name of the project.
- Domain*:
The domain of the server where the project is served.
- Algorithm type*:
Fill in the type of algorithms that will optionally be applied to the image data in this project. Values can currently only be “cad4tb”.
- Series are standalone:
Checked: all uploaded series are assumed to be independent of each other. For each series, a new patient and study will be created in the database. If non-dicom files will be uploaded to the project/archive which do not follow default filename conventions, this box needs to be checked. Each file will then be given a new PatientID, default StudyInstanceUID and SeriesInstanceUID which is the same as the filename.
Not checked: all uploaded cases can be related to each other. When multiple series or studies of the same patient are uploaded, these will be linked together in the database.
- User uid:
UUID of the user to which this project is coupled on the license server. Before a series in the project can be processed using an Algorithm, the user on the license server will be checked for available credits. If the user has credits left, the credits will be lowered by one for each time an algorithm is used to process a new case. When the same case is processed again, no extra credits will be deducted.
When the field is left empty, there will be no check on credits and the series can always be processed using an Algorithm.
- Data lifespan (days):
Patient data of the project will periodically be removed after the specified days have passed. Default is -1, which means data will not be removed at any time. Any value greater than 0 means data will be removed after speficified days have passed since its creation. This value cannot be 0 and it also cannot be lower than -1.
- Archives:
Can optionally be set here or see section Archive for more details.
- Slug:
This field is not visible on the admin but contains the slug of the project. The slug is also used in the url of the cloudviewer when viewing cases in a project. In the slug of the project, special characters and spaces are removed. The slug is the project-value that should be used in the API calls, see Section API v1.
* Required fields
3.3. Archive
To add a new archive, click the Add button (or Add archive), and to change an existing archive, click on the name of the archive you want to change. This will open a new page to edit the archive (Fig. 3.6).
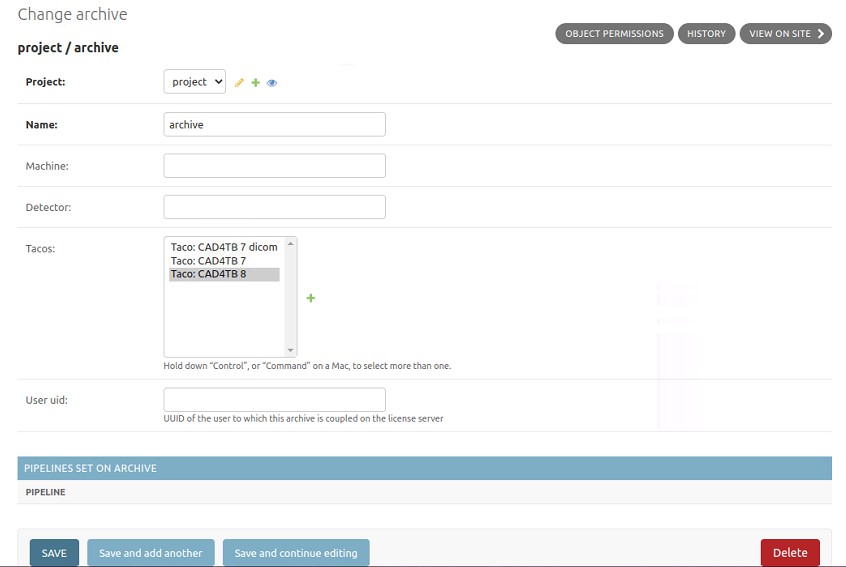
Fig. 3.6 Edit archive
The following fields are shown:
- Project*:
The Project in which the archive resides.
- Name*:
The name of the archive.
- Machine:
Optional machine that is registered to the archive.
- Detector:
Optional detector type that is registered to the archive.
- Tacos:
Taco that will be applied when a new series is imported into the archive. It is possible to select multiple tacos simultaneously.
- User uid:
UUID of the user to which this archive is coupled on the license server. Before a series in the archive can be processed using an Algorithm, the user on the license server will be checked for available credits. If the user has credits left, the credits will be lowered by one for each time an algorithm is used to process a new case. When the same case is processed again, no extra credits will be deducted.
When the field is left empty, there will be no check on credits and the series can always be processed using an Algorithm. The Archive User uid field has priority over the Project User uid field.
- Slug:
This field is not visible on the admin but contains the slug of the archive. The slug is also used in the url of the cloudviewer when viewing cases in an archvie. In the slug of the archive, special characters and spaces are removed. The slug is the archive-value that should be used in the API calls, see Section API v1.
* Required fields
After all required fields have been filled in, the archive can be saved, by pressing the Save button.
3.4. Patient
Note
Creation or editing of patient objects should only be done by the software itself. It is not advised to change any fields of these objects manually.
The patient object contains patient specific tags which are generally derived from the Series object that was last imported with that patient. These tags include for example the Patient ID, Patient Name, Patient Birthdate etc. Not all of the values are visible on the admin page.
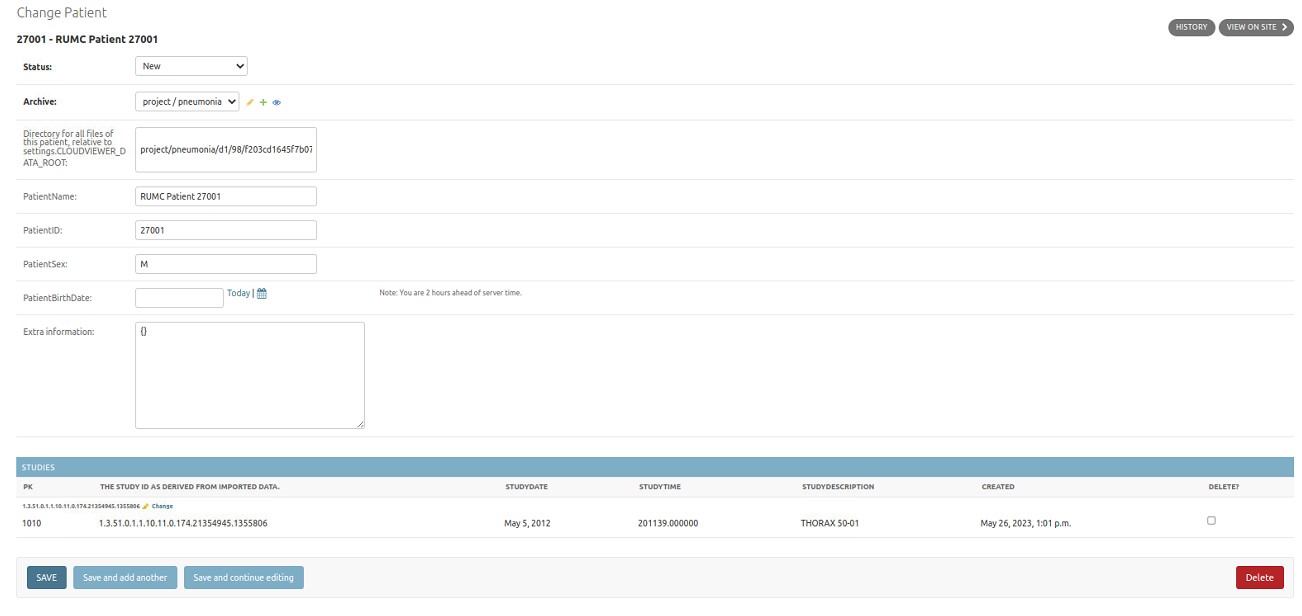
Fig. 3.7 Edit patient
3.5. Study
Note
Creation or editing of study objects should only be done by the software itself. It is not advised to change any fields of these objects manually.
The study object contains study specific tags which are generally derived from the Series object that was last imported with that study. These tags include for example the Study Date, Study Time. Not all of the values are visible on the admin page.
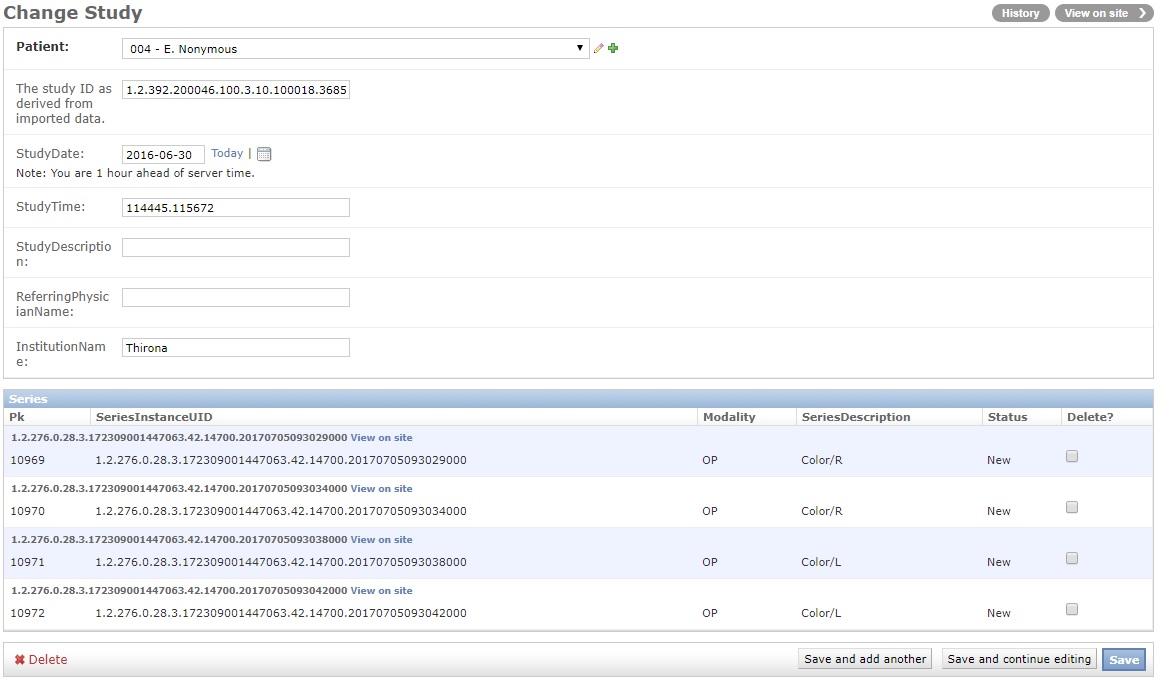
Fig. 3.8 Edit study
3.6. Series
Note
Creation or editing of series objects should only be done by the software itself. It is not advised to change any fields of these objects manually.
The series object contains series specific tags which are generally derived from series object that was imported. These tags include for example the Series Date, Series Time. Not all of the values are visible on the admin page.

Fig. 3.9 Edit series
3.7. Instance
Note
Creation or editing of instance objects should only be done by the software itself. It is not advised to change any fields of these objects manually.
The instance object contains instance specific tags which are generally derived from instance object that was imported. These tags include for example the SOPInstanceUID, Image Number. Not all of the values are visible on the admin page.
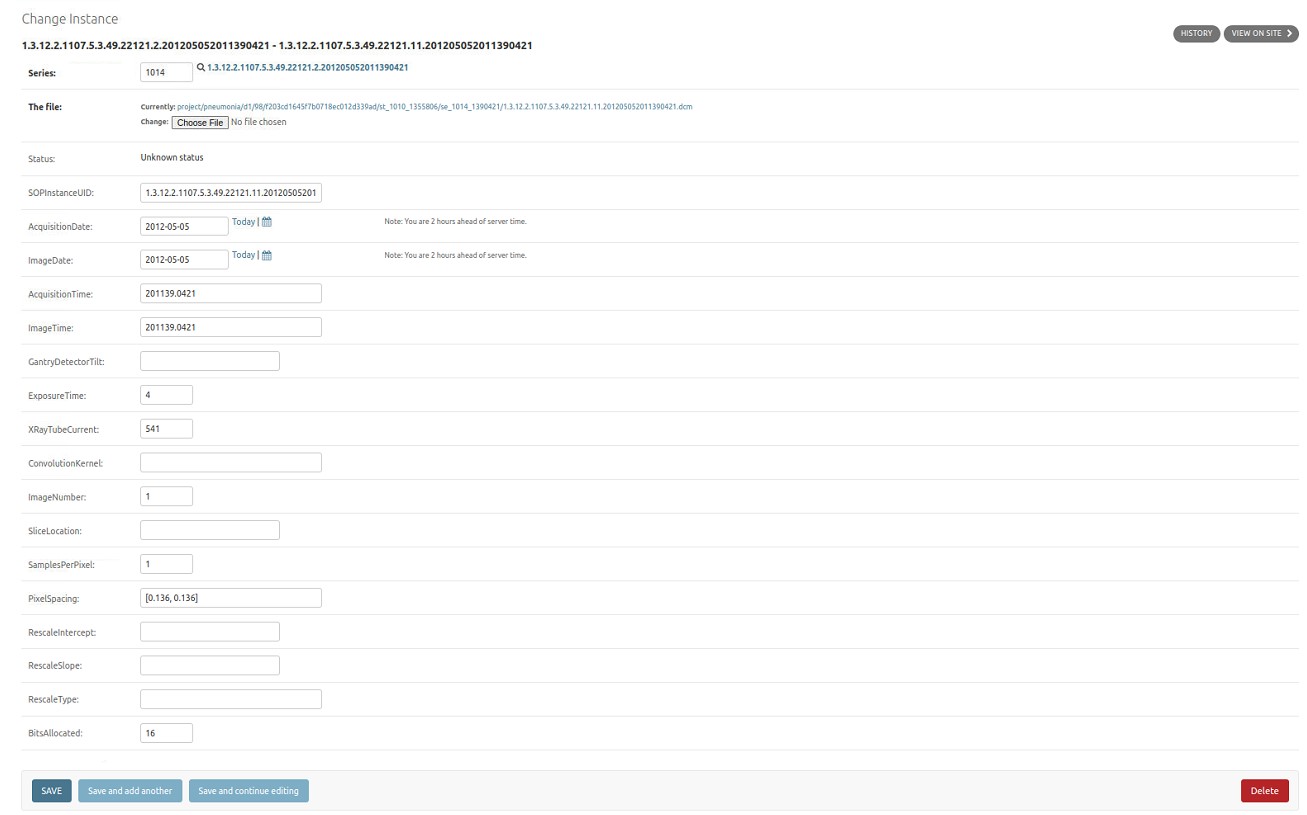
Fig. 3.10 Edit instance